
The AI lifecycle is the iterative process of moving from a business problem to an AI solution that solves that problem. Each of the steps in the life cycle is revisited many times throughout the design, development, and deployment phases.
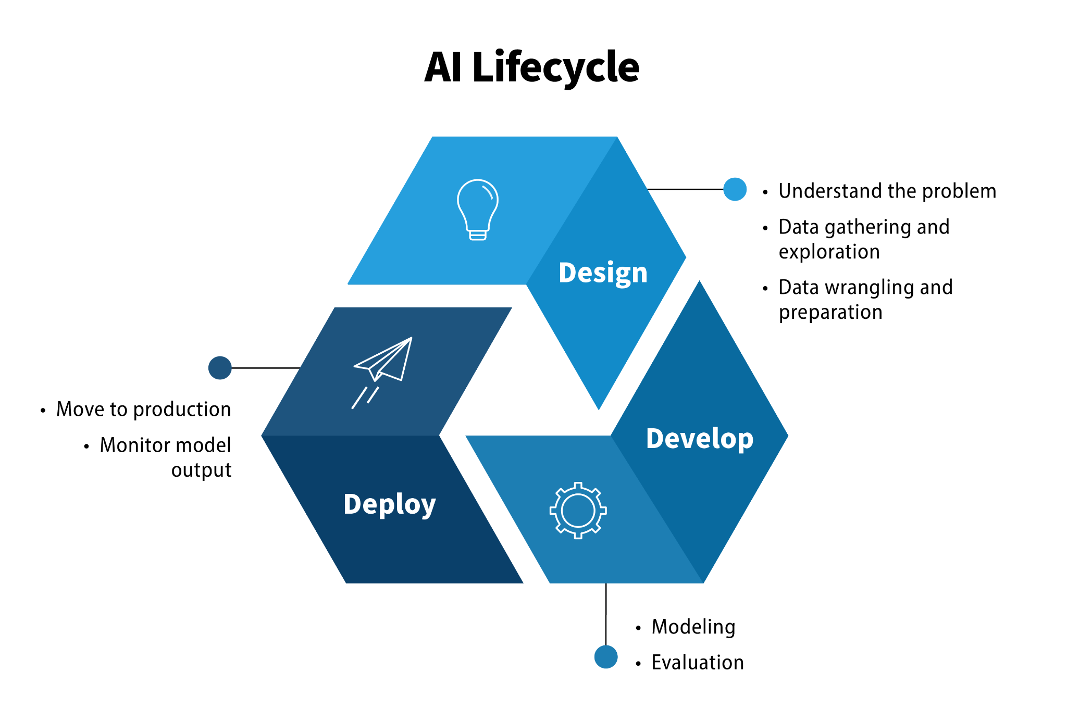
Design
-
Understand the problem: To share your team’s understanding of their mission challenge, you first have to identify the key project objectives and requirements. Then define the desired outcome from a business perspective. Finally, determining AI will solve this problem. Learn more about this step in the framing AI problems section.
-
Data gathering and exploration: This step deals with collecting and evaluating the data required to build the AI solution. This includes discovering available data sets, identifying data quality problems, and deriving initial insights into the data and perspectives on a data plan.
-
Data wrangling and preparation: This phase covers all activities to construct the working data set from the initial raw data into a format that the model can use. This step can be time consuming and tedious, but is critically important to develop a model that achieves the goals established in step 1.
- No AI solution will succeed without clearly and precisely understand the business challenge being solved and the desired outcome.
- Data is the foundation of any AI solution. Without clearly understanding of the data required and the make up of that data, a model cannot use it.
- Data preparation is often the hardest and most time-consuming phase of the AI lifecycle.
Develop
- Modeling: This step focuses on experimenting with data to determine the right model. Often during this phase, the team trains, tests, evaluates, and retrains many different models to determine the best model and settings to achieve the desired outcome.
The model training and selection process is interactive. No model achieves best performance the first time it is trained. It is only through iterative fine-tuning that the model is honed to produce the desired outcome. Learn more about types of machine learning and models in Chapter 1.
Depending on the amount and type of data being used, this training process may be very computationally expensive–meaning it requires special equipment to provide enough computing power and cannot be performed on a normal laptop. See Chapter 5 to learn more about infrastructure to support AI development.
- Evaluation: Once one or more models have been built that appear to perform well based on relevant evaluation metrics, test the models on new data to ensure they generalize well and meet the business goals.
As this step is particularly critical, we discuss it in much greater detail in the test and evaluation section.
Deploy
-
Move to production: Once a model has been developed to meet the expected outcome and performs at a level determined ready for use on live data, deploy it into a production environment. In this case, the model will take in new data that was not a part of the training cycle.
-
Monitor model output: Monitor the model as it processes this live data to ensure that it is adequately able to produce the intended outcome—a process known as generalization, or the model’s ability to adapt properly to new, previously unseen data. In production, models can “drift,” meaning that the performance will change over time. Careful monitoring of drift is important and may require continuous updating of the model.
As with any logic and software development, use an agile approach to continually retain and refresh the model. However, AI systems require extra attention. They must undergo rigorous and continuous monitoring and maintenance to ensure they continue to perform as trained, meet the desired outcome, and solve the business challenges.