
Data governance and management are central to identifying AI use cases and developing AI applications. Data governance is the exercise of authority and control (planning, monitoring, and enforcement) over data assets.1
Though Chief Data Officers (CDOs) and their counterparts have many resources available to them, we are presenting some of the key takeaways for the benefit of all those interested in data governance, especially as it relates to moving towards AI.
Legislation and guidance
In recent years, data governance and management have been codified into statute via The Foundations for Evidence-Based Policymaking Act2 (Evidence Act) that requires every executive branch agency to establish a Chief Data Officer (CDO) and identifies three pillars of work for which the CDO bears responsibility: data governance; the Open, Public, Electronic, and Necessary (OPEN) Government Data Act3; and the Paperwork Reduction Act4 (PRA).
This legal framework assigns the CDO the area of responsibility for “lifecycle data management” among others to improve agencies’ data management.
Offering further guidance, the Federal Data Strategy5, which describes 10 principles, and 40 practices designed to help agencies and the federal government improve their data governance practices. Find more details about implementing the Federal Data Strategy at strategy.data.gov.
Data governance organization
M-19-23, issued by the Office of Management and Budget (OMB) and titled “Phase I Implementation for the Foundations for Evidence-Based Policymaking Act of 2018,” provides implementation guidance pertaining to the Evidence Act. It states that each agency must establish an agency data governance body chaired by the CDO by September 2019 to support implementing Evidence Act activities6. The 2019 Federal Data Strategy (FDS) Year One Action Plan administers similar requirements7.
In executing the Evidence Act and corresponding guidance, practical requirements have been found for resource allocation, technical leadership, and practitioner and user input.
Many avenues address these requirements organizationally. Combining any three of these requirements may work for agencies depending on their specific factors. Agencies who would like to separate these requirements into separate organizational functions might do so with the organizational charts and description below:
- Data Governance Steering Committee - Chaired by the CDO (mandated in OMB 19-23), the Committee makes resourcing and policy decisions for enterprise and lifecycle data management.
- Data Governance Advisory Group - The Group collects user and practitioner needs from the enterprise, generates recommended solutions, and prepares decision documents and corresponding materials regarding data policy and resourcing for the CDO and steering committee.
- Working Groups / Communities of Practice -Practitioners who may or may not be involved in advisory group activities. These groups bring specific data governance and management needs to the advisory group to judge.
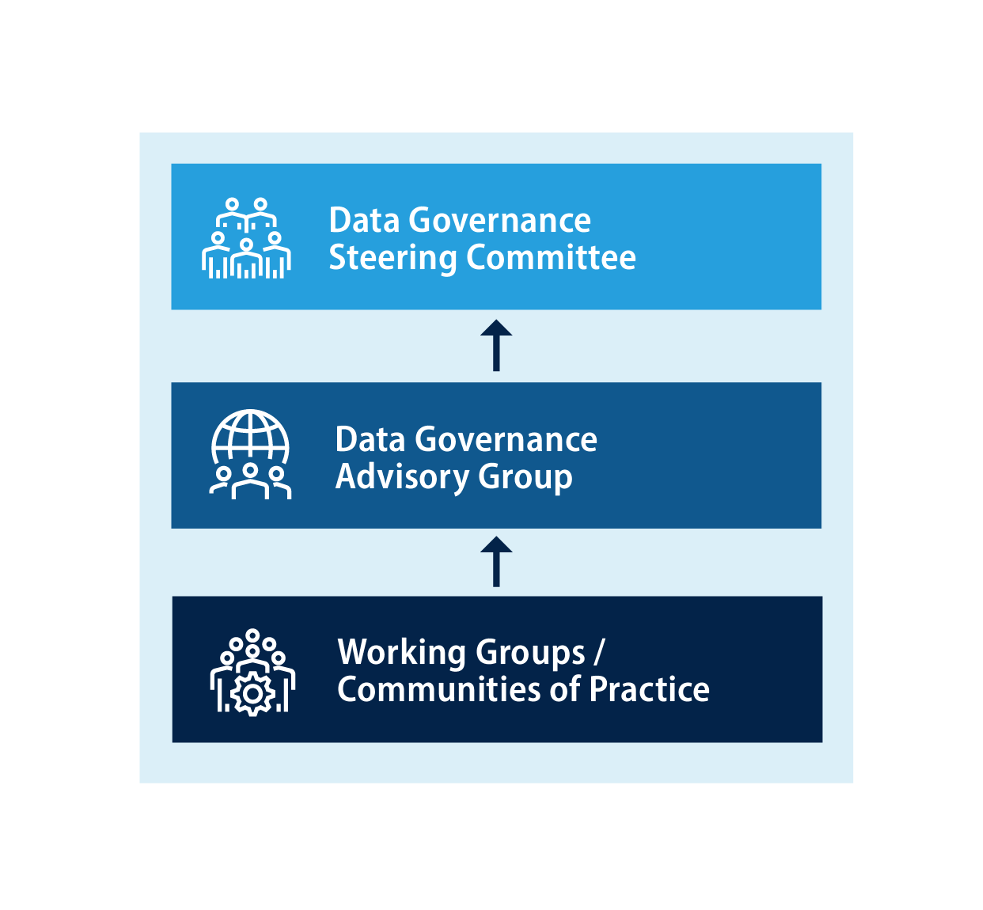
Establishing a multi-tier governance structure consisting of working groups, advisory boards, and decision-making bodies can distribute decision-making authority across tiers so activities and decisions can be made quickly. Consider elevating decisions only when they cross a defined threshold like resource allocation or level of effort.
Data governance enables organizations to make decisions about data. Establishing data governance requires assigning roles and responsibilities to perform governance functions such as:
- data strategy, policy, and standards
- oversight and compliance
- sponsoring and reporting related to data management projects
- issue elevation and resolution
Example outputs of data governance activities include (but are not limited to):
- data governance framework
- data strategy and policies
- data asset inventories
- data quality plans
- data management scorecards
- business glossary
- communications plan
- data management processes
- best practices & lessons learned
- workforce skills assessment
Data lifecycle management through metadata tagging
Data lifecycle management is the development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycles8. Data management in the context of this guide focuses on the data lifecycle as it moves through an AI project.
Many AI projects are iterative or involve significant monitoring components. Any given dataset is not itself static and can quickly change as the project uncovers new insights. Thus, we need ways to manage those updates, additions, and corrections.
Data is an asset that has a value in business and economic terms. Information on data sources and their subsequent use can be captured, measured, and prioritized much like business decisions of physical inventory assets.
Secondly, data management is multidisciplinary. This activity requires a broad range of perspectives and interactions across many different classes of “users” that make up the IPT, including data scientists, engineers, mission owners, legal professionals, security experts, and more. Using existing data governance processes to engage those stakeholders is essential to effectively managing data.
Data management activities start with identifying and selecting data sources, framed in the context of business goals, mission-defined use cases, or project objectives. As you identify data sources, have engineering teams integrate them into the overall data flow, either through data ingestion or remote access methods. Include a clear description of the data through relevant metadata with datasets as they are published.
Effective data governance will influence resourcing decisions based on the overall business value of datasets. In order to influence these resourcing decisions, get usage metrics and business intelligence across your data inventory.
User research and use case development help governance bodies understand high-impact datasets across different members of the IPT or mission areas.
One example of data lifecycle management is standardizing metadata captured for new data sources by populating a data card used to describe the data.9 Each dataset should contain common interoperable metadata elements that include, but are not limited to, the following:
- data source origin
- originating collection authority and organization
- format and type of data (e.g. jpeg, text, wav, etc)
- size of data
- periodicity of data transfer (one-time batch, every two weeks, real-time streaming)
- requisite security controls
- pre-processing or transformations applied to the data
- points of contact for data suppliers, owners, and stewards
- data makeup and features, including obvious and non-obvious constraints, such as variable names and meanings
While minimum tagging requirements vary across different organizations, the list above is provided as a general guideline. For operations that are highly specific or deal with high-impact or sensitive data, the receiving organization may need to capture more metadata fields earlier in the data lifecycle.
One example of this is access rights and handling, need-to-know, and archiving procedures associated with classified data, which requires highly restricted and governed data handling procedures.10
Other descriptive dimensions include the mission or use case context. For example, metadata can be applied to datasets that detail information on the Five Vs, listed below:
- Volume
- Velocity
- Veracity
- Variety
- Variability
In addition to the Five Vs, apply use case specific metadata to datasets, which further supports future data curation and discovery efforts. Some examples of use case specific metadata, as noted in the NIST Big Data Working Group Use Case publication11, include:
- use case title
- description
- goals
- current solutions (hardware, software, etc.)
- additional stakeholders/contributors
Once data is accurately described, it can be cataloged, indexed, and published. Data consumers can then easily discover datasets related to their specific development effort. This metadata also sets the basis for implementing security procedures that govern data access and use.
Data should be securely accessed and monitored throughout its useful lifespan, and properly archived according to handling procedures set forth by the original data owner.
Footnotes
-
Earley, Susan, and Deborah Henderson. 2017. DAMA-DMBOK: data management body of knowledge. ↩
-
“The Foundations for Evidence-Based Policymaking Act of 2018.” P.L.115-435. Jan. 14, 2019. https://www.congress.gov/115/plaws/publ435/PLAW-115publ435.pdf ↩
-
The OPEN Data Act is part of P.L.-115-435. ↩
-
The Federal Data Strategy https://strategy.data.gov/ ↩
-
In addition to Evidence Act, administration policy published by the Office of Management and Budget titled “Managing Information as an Asset” (M-13-13) declares that executive departments and agencies “must manage information as an asset throughout its life cycle to promote openness and interoperability, and properly safeguard systems and information.” Corresponding policy requirements detailed in M-13-13 include the adoption of data standards, the development of common core metadata, and the creation and maintenance of an enterprise data inventory. ↩
-
Ibid. Pg. 20. ↩
-
“Draft 2019-2020 Federal Data Strategy Action Plan.” Federal Data Strategy Development Team. June 2019. Pg. 11. https://strategy.data.gov/assets/docs/draft-2019-2020-federal-data-strategy-action-plan.pdf ↩
-
Earley, Susan, and Deborah Henderson. 2017. DAMA-DMBOK: data management body of knowledge. ↩
-
Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. “Datasheets for Datasets.” ArXiv:1803.09010 [Cs], March 19, 2020. http://arxiv.org/abs/1803.09010
DISCLAIMER: The chapter includes hypertext links, or pointers, to information created and maintained by other public and/or private organizations. We provide these links and pointers only for your information and convenience. When you select a link to an outside website, you are leaving the GSA.gov site and are subject to the privacy and security policies of the owners/sponsors of the outside website. GSA does not control or guarantee the accuracy, relevance, timeliness, or completeness of information contained on a linked website. We do not endorse the organizations sponsoring linked websites and we do not endorse the views they express or the products/services they offer. The content of external, non-Federal websites is not subject to Federal information quality, privacy, security, and related guidelines. We cannot authorize the use of copyrighted materials contained in linked websites. Users must request such authorization from the sponsor of the linked website. We are not responsible for transmissions users receive from linked websites. We do not guarantee that outside websites comply with Section 508 (accessibility requirements) of the Rehabilitation Act. ↩
-
“Intelligence Community Enterprise Data Header” Office of the Director of National Intelligence. https://www.dni.gov/index.php/who-we-are/organizations/ic-cio/ic-cio-related-menus/ic-cio-related-links/ic-technical-specifications/enterprise-data-header ↩
-
NIST Big Data Interoperability Framework: Volume 3, Big Data Use Cases and General Requirements [Version 2]. June 26, 2018 https://www.nist.gov/publications/nist-big-data-interoperability-framework-volume-3-big-data-use-cases-and-general ↩